您现在的位置是:主页 > 运维部署 >
高性能 DB 架构设计
2021-01-07 09:52:23运维部署 146058人已围观
高性能 DB cluster:读写分离
-
大部分情况下做架构设计主要都是基于已有的成熟模式,结合业务和团队的具体情况,进行一定的优化或者调整
-
即使少部分情况需要进行较大的创新,前提也是需要对已有的各种架构模式和技术非常熟悉
-
不管是为了满足业务发展的需要,还是为了提升自己的竞争力,RDBMS 厂商(Oracle、DB2、MySQL … 等)在优化和提升单一 DB server 的性能方面也做了非常多的技术优化和改进
但业务发展速度和数据增长速度,远远超出 DB 厂商的优化速度
-
互联网业务兴起之后,海量用户加上海量数据的特点,单个 DB server 已经难以满足业务需要,必须考虑 DB cluster 的方式来提升性能
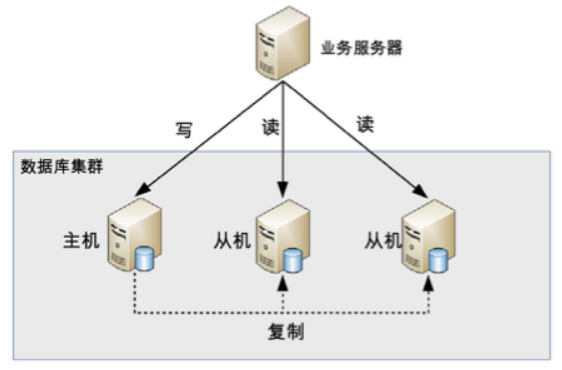
读写分离原理
- 读写分离的基本原理是将 DB 读写操作分散到不同的 node 上
-
读写分离的基本实现是:
- DB server 搭建 master/slave cluster ,one master/one slave、one master/multiple slave 都可以
- DB master 负责 read/write 作业,slave 只负责 read 作业
- DB master 通过複製将数据同步到 slave,每台 DB server 都储存了所有的业务相关资料
- 线上服务将 write 作业发给 DB master,将 read 作业发给 DB slave
-
需要注意的是,这裡用的是 master/slave cluster,而不是 `primary/backup cluster”
-
slave 需要提供读数据的功能的;而 backup 一般被认为仅仅提供备份功能,不提供存取功能
-
读写分离的实现逻辑并不複杂,但是会引入两个複杂度:主从複製延迟 & 分配机制
主从複製延迟
-
以 MySQL 为例,主从複製延迟可能达到 1 秒,如果有大量数据同步,延迟 1 分钟也是有可能的
-
解决主从複製延迟有几种常见的方法:
- write 操作后的 read 操作指定发给 DB master server:和业务强绑定,对业务的侵入和影响较大
- 读 slave 失败后再读一次 master:如果有很多二次读取,将大大增加主机的 read 操作压力
- 关键业务 read/write 操作全部指向 master,非关键业务採用读写分离
分配机制
将 read/write 操作区分开来,然后访问不同的 DB server ,一般有两种方式:程序程式封装和 middleware 封装
程式封装
程式封装指在程式中抽象出一个数据访问层(or 中间层封装),实现读写操作分离和 DB server 连接的管理
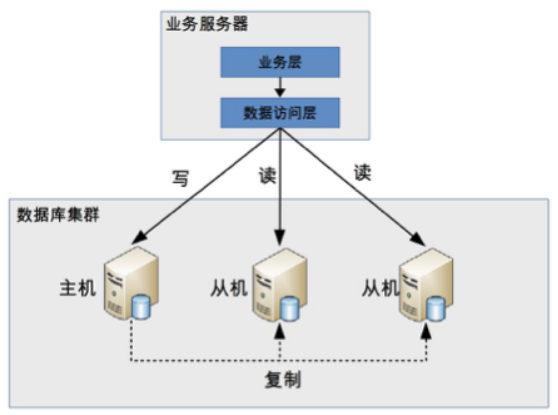
程式封装的方式具备几个特点:
- 实现简单,而且可以根据业务做较多定製化的功能。
- 每个程式语言都需要自己实现一次,无法通用,如果一个业务包含多个程式语言写的多个子系统,则重複开发的工作量比较大。
- 故障情况下,如果主从发生切换,则可能需要所有系统都修改设定 & 重启。
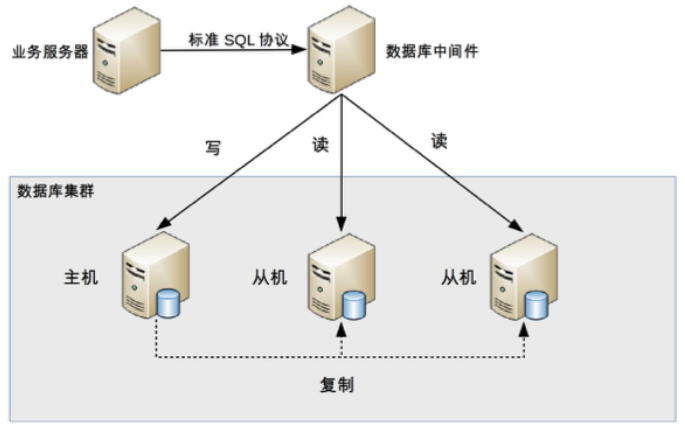
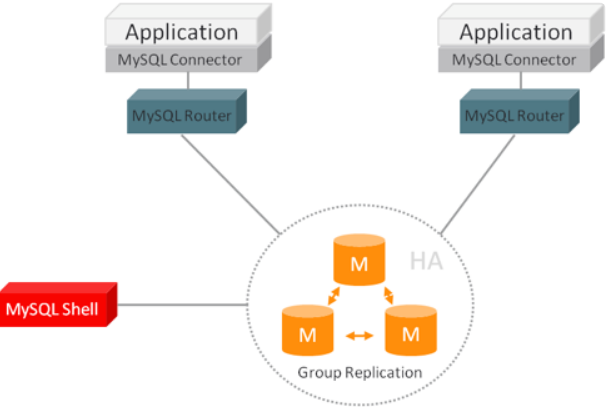
middleware 封装
-
middleware 封装指的是独立一套系统出来,实现读写操作分离和 DB server 连接的管理
-
middleware 对服务提供 SQL 兼容的协议,服务本身无须自己进行读写分离
-
DB middleware 的方式具备的特点是:
- 能够支持多种程式语言,因为 DB middleware 对服务提供的是标准 SQL 接口
- DB middleware 要支持完整的 SQL 语法和 DB server 的协议(例如:MySQL client 与 server 的连接通讯协定),实现比较複杂,细节特别多,很容易出现 bug,需要较长的时间才能稳定
- DB middleware 自己不执行真正的读写操作,但所有的 DB 操作请求都要经过 middleware,因此对于 middleware 的性能要求也会需要很高
- DB master/slave 切换对服务来说是无感的,DB middleware 可以侦测 DB server 的主从状态(例如:向某个测试 table 写入一笔资料,成功的就是 master,失败的就是 slave)
-
由于 DB middleware 的複杂度要比程式封装高出许多,一般情况下建议採用程序语言封装的方式,或者使用成熟的开源 DB middleware(例如:MySQL Router, Apache ShardingSphere, Mycat)
讨论整理精华
-
不需要有性能问题就马上进行读写分离,而是应该先优化(例如:优化 slow query,调整不合理的业务逻辑,引入 cache 等,只有确定系统没有优化空间后,才考虑读写分离或者 cluster
-
在单机 DB 情况下,table 加上 index 一般对查询有优化作用却影响写入速度,读写分离后可以单独对 read DB 进行优化,write DB 上减少 index,对读写的能力都有提升,且读的提升更多一些
-
如果并发写入特别高,单机写入无法支撑,就不适合加入 index 的方式解决(加入 index 只会加重写入负担)
可改用 cache 技术或者程序优化的方式满足要求
-
因为业务查询的关係,multiple table 之间的关联,聚合,很难避免,但是查询的条件太多,很动态,设计 cache 的方式:
- 按照 80/20 原则,选出佔访问量 80% 的前 20% 的请求条件进行 cache
- 大部分人的查询不会每次都非常多条件,以手机为例,查询苹果加华为的可能佔很大一部分
-
交易型业务 cache 应用不多, cache 一般都会用在查询类业务上 (事实上大部分业务场景可能并不需要读写分离)
-
读写分离适用于单一 server 无法满足所有请求的场景,从请求类型的角度对 server 进行拆分;在要求硬体资源能够支撑的同时,对程式效能也会有更高的要求
-
一次删除大量资料可能造成 master/slave 不同步 => 线上 delete 每次不能超过 1000 笔资料,超过就定时循环操作
-
middleware 并不是性能上有优势,而是可以跨语言夸系统重複使用,大公司才有实力做(否则就选择现有的成熟开源方案)
-
同步速度主要受网路延迟影响,和硬体关係不大
-
如果 cache 能承受业务请求,其实一般不用做读写分离,例如论坛的帖子浏览场景
高性能 DB cluster:分库分表
读写分离分散了 DB 读写操作的压力,但没有分散储存压力,当数据量达到千万甚至上亿条的时候,单台 DB server 的储存能力会成为系统的瓶颈;这样的状况会造成以下问题:
-
数据量太大,读写的性能会下降,即使有 index,index 也会变得很大,性能同样会下降。
-
数据文件会变得很大, DB backup & restore 需要耗费很长时间
-
数据文件越大,极端情况下丢失数据的风险越高(例如,机房火灾导致 DB master/slave 都发生故障)
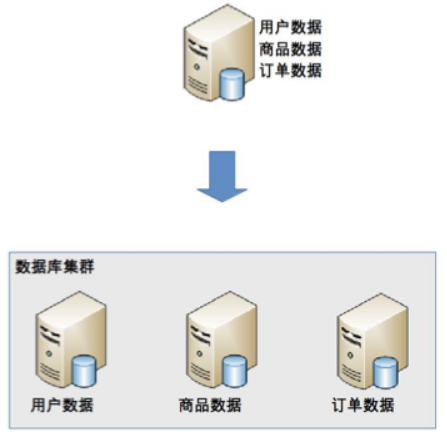
分库
-
业务分库指的是按照业务模组将数据分散到不同的 DB server
-
虽然业务分库能够分散储存和访问压力,但同时也带来了新的问题:
-
- join 操作问题:原本在同一个 DB 中的 table 分散到不同 DB 中,导致无法使用 SQL 的 join 查询
-
- 事务问题:业务分库后,table 分散到不同的 DB 中,无法通过事务统一修改
-
- 成本问题:业务分库同时也带来了成本的代价,本来 1 台 server 可以搞定的事情,现在要 3 台,如果考虑备份,那就是 2 台变成了 6 台
-
-
对于小公司初创业务,并不建议一开始就这样拆分,主要有几个原因:
- 初创业务存在很大的不确定性,业务不一定能发展起来,业务开始的时候并没有真正的储存和访问压力,业务分库并不能为业务带来价值
- 业务分库后,表之间的 join 查询、 DB 事务无法简单实现了
- 业务分库后,因为不同的数据要读写不同的 DB,程式中需要增加根据数据类型对应到不同 DB 的逻辑,增加了工作量;而业务初创期间最重要的是快速实现、快速验证,业务分库会拖慢业务节奏
-
如果业务真的发展很快,岂不是很快就又要进行业务分库了? 那为何不一开始就设计好呢?
- 这裡的”如果”事实上发生的概率比较低
- 如果业务真的发展很快,后面进行业务分库也不迟
- 单台 DB server 的性能其实也没有想像的那麽弱
-
对于业界成熟的大公司来说,由于已经有了业务分库的成熟解决方案,并且即使是尝试性的新业务,用户规模也是海量的,这与前面提到的初创业务的小公司有本质区别,因此最好在业务开始设计时就考虑业务分库
分表
-
如果业务继续发展,同一业务的单一 table 数据也会达到单台 DB server 的处理瓶颈
-
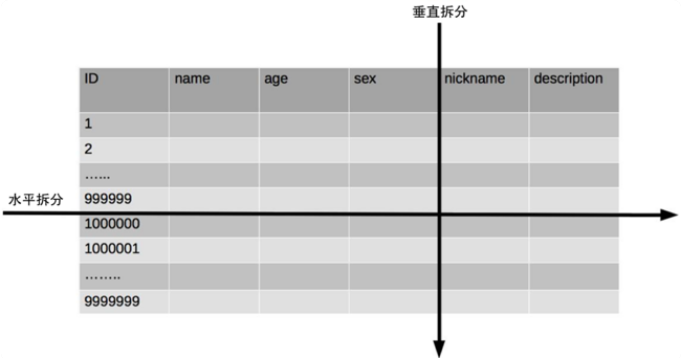
单一 table 数据拆分有两种方式:
- 垂直分表:对应到表的切分就是表记录数相同但包含不同的 colume
-
水平分表:对应到表的切分就是表的 colume 相同但包含不同的 row data
-
实际架构设计过程中并不侷限切分的次数,可以切两次,也可以切很多次
-
单一 table 进行切分后,是否要将切分后的多个 table 分散在不同的 DB server 中,可以根据实际的切分效果来确定
-
单一 table 切分为多个 table 后,新的 table 即使在同一个 DB server 中,也可能带来可观的性能提升
-
如果单一 table 拆分为多个 table 后,单台 server 依然无法满足性能要求,那就不得不再次进行业务分库的设计了
垂直分表引入的複杂性
-
垂直分表适合将表中某些不常用且佔了大量空间的 colume 拆分出去
-
垂直分表引入的複杂性主要体现在 table 操作的数量要增加
水平分表引入的複杂性
路由
常见的路由算法:
-
范围路由:选取有序的 data colume (例如:integer、timestamp … 等等)作为路由的条件,不同分段分散到不同的 DB table 中
- 複杂点:主要体现在分段大小的选取上,分段太小会导致切分后子表数量过多,增加维护複杂度
- 优点:可以随著数据的增加平滑地扩充新的表
- 缺点:分佈不均匀
-
Hash 路由:选取某个 colume(或者某几个 colume 组合也可以)的值进行 Hash 运算,然后根据 Hash 结果分散到不同的 DB table 中
- 複杂点:主要体现在初始 table 数量的选取上,table 数量太多维护比较麻烦,table 数量太少又可能导致单一 table 性能存在问题
- 优点:table 分佈比较均匀
- 缺点:扩充新的 table 很麻烦,所有数据都要重分佈
-
配置路由:配置路由就是路由表,用一张独立的 table 来记录路由信息
- 优点:设计简单,使用起来非常灵活
- 缺点:必须多查询一次,会影响整体性能;而且路由表本身如果太大(例如:几亿条数据),性能同样可能成为瓶颈
join 操作
平分 table 后,数据分散在多个 table 中,如果需要与其他 table 进行 join 查询,需要在业务程式或者 DB middleware 中进行多次 join 查询,然后将结果合併
count() 操作
水平分表后,虽然物理上数据分散到多个表中,但某些业务逻辑上还是会将这些 table 当作单一 table 表来处理
常见的处理方式有下面两种:
-
count() 相加:实现简单,缺点就是性能比较低
-
count 资料表
- 性能要大大优于 count() 相加的方式
- 也增加了 DB 的写压力
- 複杂度增加不少,对子表的操作要同步操作”记录数表”,如果有一个业务逻辑遗漏了,数据就会不一致
对于一些不要求 count 数据即时保持精确的业务,也可以通过后台定时更新 count 资料表
order by 操作
水平分表后,数据分散到多个子表中,排序操作无法在 DB 中完成,只能由业务程式或者 DB middleware 分别查询每个子表中的数据,然后彙总进行排序
实现方法归纳
-
和 DB 读写分离类似,分库分表具体的实现方式也是程式封装和middleware 封装,但实现会更複杂
-
读写分离实现时只要识别 SQL 操作是 read 作业还是 write 作业,通过简单的判断 SELECT、UPDATE、INSERT、DELETE 几个关键字就可以做到
-
分库分表的实现除了要判断操作类型外,还要判断 SQL 中具体需要操作的 table、操作函数(例如:count)、order by、group by 操作等,然后再根据不同的操作进行不同的处理
讨论整理精华
-
DB 优化的方向顺序建议:
- 进行硬体优化,例如:将 HDD 换成 SSD、增加 CPU core
- 先做 DB server 的优化(例如:增加 index, 优化 slow query)
- 引入 cache 技术(例如:redis)减少 DB 压力
- 服务与 DB table 优化,重构(例如:根据业务逻辑对程序逻辑做优化,减少不必要的查询)
- 在这些操作都不能大幅度优化性能的情况下,不能满足将来的发展,再考虑分库分表,但也要有预估性
-
针对 Mysql,发现如果 colume 是 blob 型态,select 时有无包含此栏位,效率差异很大啊,这个是什麽原因?
blob 的栏位是和 row data 分开储存的,而且 disk 上并不是连续的,因此 select blob 栏位会让 disk 进入 random I/O 模式
-
分库分表的实施前提:
- DB 存在性能问题,且用加索引、 slow query 优化、 cache 和读写分离都无法彻底解决问题的时候
- 複杂查询对应的单一 table 数据量级一般超过千万以上,或简单查询的单一 table 数据量级一般超过 5000 万以上
- 对一致性要求不是特别高,只要求最终一致性
- 用 Hadoop 等大数据技术,因为业务需求、技术成本、时间成本无法解决该问题
-
分表评估:
- 业务对数据的操作主要集中在某些 colume 上,比较适合垂直分表
- 业务对数据的操作在整个表层面较均匀分佈,适合水平分表
-
分库使用时机:
- 业务不複杂,但整体数据量已影响了 DB 的性能
- 业务複杂,需要分模组由不同开发团队负责开发,这个时候使用分库可以减少团队间交流
-
分表时机:单一 table 数据量太大,拖慢了 SQL 操作性能
-
并不是 DB 性能不够的时候就分库分表,提升 DB 性能方式很多,若有其他能在单一 DB 操作的方式则毫不犹豫使用,因为使用分表有固有的複杂性(join操作,事务,order by … 等)
-
通常 DB 刚表现出压力的时候,大部分原因不是因为业务真的发展到 DB 撑不住了,而是很多 slow query 导致的
高性能 NoSQL

-
RDBMS 存在如下缺点:
- 储存的是 colume data,无法储存数据结构
- schema 扩展很不方便(修改时可能会长时间锁表)
- 在大数据场景下 I/O 较高(做统计)
- 全文搜寻功能比较弱(全文搜寻只能使用 like 进行整表扫瞄匹配,性能非常低)
-
NoSQL 方案带来的优势,本质上是牺牲 ACID 中的某个或者某几个特性
-
不能盲目地迷信 NoSQL 是银弹,而应该将 NoSQL 作为 SQL 的一个加强方式
-
常见的 NoSQL 方案分为 4 类:
- Key/Value store:解决 RDBMS 无法储存数据结构的问题,以 redis 为代表。
- Document DB:解决 RDBMS 强 schema 约束的问题,以 MongoDB 为代表。
- Colume-Based DB:解决 RDBMS 大数据场景下的 I/O 问题,以 HBase 为代表。
- 全文搜寻引擎:解决 RDBMS 的全文搜寻性能问题,以 Elasticsearch 为代表。
Key/Value store
-
redis 是 Key/Value store 的典型代表,它是一款 open source 的高性能 Key/value cache 和储存系统
-
RDBMS 实现 Key/Value 的功能很麻烦,而且需要进行多次 SQL 操作,性能很低
-
redis 的缺点主要体现在并不支持完整的 ACID 事务
redis 的事务只能保证隔离性(isolation)和一致性(consistency),无法保证原子性(atomic)和持久性(durability)
-
虽然 redis 并没有严格遵循 ACID 原则,但实际上大部分业务也不需要严格遵循 ACID 原则
-
在设计方案时,需要根据业务特性和要求来确定是否可以用 redis,而不能因为 redis 不遵循 ACID 原则就直接放弃
Document DB
-
Document DB 最大的特点就是 no-schema,可以储存和读取任意的数据
-
目前绝大部分 Document DB 储存的数据格式是 JSON(or BSON)
-
Document DB的 no-schema 特性,给业务开发带来了几个明显的优势:
- 新增栏位简单
- 历史数据不会出错
- 可以很容易储存複杂数据
-
Document DB 的这个特点,特别适合电商和游戏这类的业务场景:
- 以电商为例,不同商品的属性差异很大
- 即使是同类商品也有不同的属性
-
上述的业务场景如果使用 RDBMS 来储存数据,就会很麻烦,而使用 Document DB,会简单、方便许多,扩展新的属性也更加容易
-
缺点:
- 不支持事务,因此某些对事务要求严格的业务场景是不能使用 Document DB的
- 无法实现 RDBMS 的 join 操作,须多次查询
Colume-Based DB
-
传统 RDBMS 被称为 Row-Based DB,优势在于:
- 业务同时读取 multiple row 时效率高
- 能够一次性完成对 row 中的多个 colume 的写操作,保证了针对 row data 写操作的原子性和一致性
-
Colume-Based DB 的优势是在特定的业务场景(海量数据进行统计)下才能体现,如果不存在这样的业务场景,那麽 Colume-Based DB 的优势也将不复存在,甚至成为劣势
-
Colume-Based DB
-
优点:
- 节省 I/O
- 具备更高的储存压缩比
-
缺点:
- 若需要频繁地更新多个 colume => 将不同 colume 储存在 disk 上不连续的空间,导致更新多个 colume 时 disk 是 random write 操作(效率极差)
- 高压缩率在更新场景下也会成为劣势,因为更新时需要将储存数据解压后更新,然后再压缩,最后写入 disk
-
优点:
-
一般将 Colume-Based DB 应用在离线的大数据分析和统计场景中,因为这种场景主要是针对部份 row 的单一 colume 进行操作,且数据写入后就无须再更新删除
全文搜寻引擎
传统的 RDBMS 通过 index 来达到快速查询的目的,但是在全文搜寻的业务场景下,index 也无能为力,主要体现在:
-
全文搜寻的条件可以随意排列组合,如果通过 index 来满足,则 index 的数量会非常多。
-
全文搜寻的模糊匹配方式,索引无法满足,只能用 like 查询,而 like 查询是 full table scan,效率非常低。
基本原理
-
全文搜寻引擎的技术原理被称为"倒排索引"(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,其基本原理是建立单词到文件的索引
-
正排索引适用于根据文件名称来查询文件内容
-
倒排索引适用于根据 keyword 来查询文件内容
使用方式
-
全文搜寻引擎的索引对象是单词和文件,而 RDBMS 的索引对象是 key 和 row,两者的术语差异很大,不能简单地等同起来
-
为了让全文搜寻引擎支持关係型数据的全文搜寻,需要做一些转换操作,即将关係型数据转换为文件数据
-
目前常用的转换方式是将关係型数据按照对象的形式转换为 JSON 文件,然后将 JSON 文件输入全文搜寻引擎进行索引
-
Elastcisearch 是分散式的文件储存方式。它能储存和检索複杂的数据结构 - 以即时的方式序列化成为 JSON 文件
-
在 Elasticsearch 中,每个 field 的所有数据都是预设被索引的。即每个字段都有为了快速检索设置的专用倒排索引
-
不像其他多数的 DB,Elasticsearch 能在相同的查询中使用所有倒排索引,并以惊人的速度返回结果
讨论整理精华
-
RDBMS 和 NoSQL DB 的选型。考虑几个指标:数据量、并发量、即时性、一致性要求、读写分佈和类型、安全性、运维性等;根据这些指标,软体系统可分成几类。
- 管理型系统(例如:运营类系统),首选 RDBMS
- 大流量系统(例如:电商单品页的某个服务),后台选 RDBMS,前台选内存型(Key/Value store)
- 日志型系统(例如:原始数据)选 Colume-Based DB,日志搜寻选倒排索引
- 搜寻型系统(例如:站内搜寻,非通用搜寻,如商品搜寻),后台选 RDBMS,前台选倒排索引。
- 事务型系统(例如:库存、交易、记账),选关係型 + cache + 一致性协议,或新型 RDBMS
- 离线计算(例如:大量数据分析),首选 Colume-Based DB,RDBMS 也可以
- 即时计算(例如:即时监控),可以选 time-series DB ,或 colume-based DB
-
将商品/订单/库存等相关基本信息放在 RDBMS 中(如MySQL,业务操作上支持事务,保证逻辑正确性),cache 可以用 redis(减少 DB 压力),搜寻可以用 Elasticsearch(提升搜寻性能,可通过定时任务定期将 DB 中的资料同步到 ES 中)
-
多种方案搭配混用必然会增加应用的複杂性与增加运维成本,但同时也带来了系统更多的灵活性
-
RDBMS 使用 index 加快查询速度;Key/Value store 使用 memory 加快查询速度;Elasticsearch 使用倒排索引加快查询速度;Colume-Based DB 使用将 colume 单独储存来加快查询速度
高性能 cache 架构
-
在某些複杂的业务场景下,单纯依靠储存系统的性能提升不够的,典型的场景有:
- 需要经过複杂运算后得出的数据,储存系统无能为力
- read-many, write less(读多写少)的数据,储存系统有心无力
-
cache 就是为了弥补储存系统在这些複杂业务场景下的不足,基本原理就是将可能重複使用的数据放到 memory 中,一次生成、多次使用,避免每次使用都去存取速度相较 memory 慢很多的储存系统
-
cache 能够带来性能的大幅提升
单台 Memcache server 简单的 key-value 查询能够达到 TPS 50,000 以上
-
cache 虽然能够大大减轻储存系统的压力,但同时也给架构引入了更多複杂性
Cache penetration
cache penetration 是指 cache 没有发挥作用,业务系统虽然去 cache 查询数据,但 cache 中没有数据,业务系统需要再次去储存系统查询数据。
通常情况下有两种情况:
储存数据不存在
-
在 cache 中找不到对应的数据,每次都要去储存系统中再查询一遍,然后返回数据不存在
cache 在这个场景中并没有起到分担储存系统访问压力的作用
-
出现一些异常情况(例如:被 hacker 攻击),故意大量访问某些读取不存在数据的业务,有可能会将储存系统拖垮
可能解决方案:
-
如果查询储存系统的数据没有找到,则直接设置一个预设值(可以是空值,也可以是具体的值)存到 cache 中,这样第二次读取 cache 时就会获取到预设值,而不会继续访问储存系统
-
使用 Bloom filter
实际应用上可能难以将所有 key 列出(例如:在分散式环境下很难完成这件事情)
cache 数据生成耗费大量时间或者资源
-
储存系统中存在数据,但生成 cache 数据需要耗费较长时间或者耗费大量资源
-
刚好在业务访问的时候 cache 失效了,那麽也会出现 cache 没有发挥作用,访问压力全部集中在储存系统上的情况
-
爬虫来遍历的时候,系统性能就可能出现问题
由于很多分页都没有 cache 数据,从 DB 中生成 cache 数据又非常耗费性能(order by limit 操作),因此爬虫会将整个 DB 全部拖慢
-
爬虫问题处理:(爬虫并非攻击)
- 识别爬虫然后禁止访问,但这可能会影响 SEO 和推广
- 做好监控,发现问题后及时处理
Cache avalanche
-
当 cache 失效(过期)后引起系统性能急剧下降的情况
-
旧的 cache 已经被清除,新的 cache 还未生成,并且处理这些请求的 thread 都不知道另外有一个 thread 正在生成 cache ,因此所有的请求都会去重新生成 cache,都会去访问储存系统,从而对储存系统造成巨大的性能压力
常见解决方法有两种:
-
更新锁:
- 对 cache 更新操作进行加锁保护,保证只有一个 thread 能够进行 cache 更新,未能获取更新锁的 thread 要嘛等待锁释放后重新读取 cache ,要嘛就返回空值或者预设值
- 分散式 cluster 的业务系统要实现更新锁机制,则需要用到分散式锁,如 ZooKeeper
-
后台更新:由后台 thread 来更新 cache ,而不是由业务 thread 来更新 cache
- 业务 thread 发现 cache 失效后,通过 message queue 发送一条消息通知后台 thread 更新 cache
- 后台更新既适应单机多 thread 的场景,也适合分散式 cluster 的场景,相比更新锁机制要简单一些
- 后台更新机制还适合业务刚上线的时候进行 cache 预热
Hotspot cache
-
虽然 cache 系统本身的性能比较高,但对于一些特别热点的数据,如果大部分甚至所有的业务请求都命中同一份 cache 数据,则这份数据所在的 cache server 的压力也很大
-
cache 热点的解决方案就是複製多份 cache 副本,将请求分散到多个 cache server 上,减轻 hotspot cache 导致的单台 cache server 压力
-
不同的 cache 副本不要设置统一的过期时间,否则就会出现所有 cache 副本同时生成同时失效的情况,从而引发 cache 雪崩效应
讨论整理精华
-
不要只从技术的角度考虑问题,结合业务考虑技术
-
将查询条件组合成字符串再计算 md5,作为 cache key,优点是简单灵活,缺点是浪费一部分 cache
-
DB 压力大就可以考虑 cache 了
-
需要监控 cache 是否很快就满了 or cache 命中率降低 … 等状况,搭配告警进行处理
-
一般分页 cache , cache id 列表,不要 cache 所有数据
-
系统不是达到一定的系统查询性能瓶颈,别一开始就用 cache
-
就算是 cache 修改频率是一分钟, cache 在这一分钟也是有很大作用的,因为一分钟可能就是几千上万次读操作了,所以不要认为一天都不修改的数据才能用 cache
-
MySQL cache & cache server 的比较:
- MySQL 第一种 cache 叫 sql 语句结果 cache ,但条件比较苛刻,程式设计师无法控制,一般 dba 都会关闭这个功能
- MySQL 第二种 cache 是 innodb buffer pool,cache 的是 disk 上的分页数据,不是 sql 的查询结果,sql 的执行过程省不了
- memcached、redis 这些实际上都是 cache sql 的结果,两种 cache 方式,性能差异是很大的
因此,可控性,性能是 DB cache 和独立 cache 的主要区别
-
一个好的 cache 设计方案应该从这几个方面入手设计:
- 什麽数据应该 cache
- 什麽时机触发 cache 和以及触发方式是什麽
- cache 的层次和粒度(网关 cache 如 nginx,本地 cache 如单机文件,分散式 cache 如 redis cluster,process 内 cache 如 global variables)
- cache 的命名规则和失效规则
- cache 的监控指标和故障应对方案
- 可视化 cache 数据(例如:redis 具体 key 内容和大小)
-
监控爬虫,发现问题后及时处理
监控 DB 的各项指标,发现逐步变慢后看看是不是爬虫,只要系统还撑得住就让它爬,撑不住就不让它爬
-
分页数据有很多排序规则,而且可能在某个时间点要上架新商品,就会有即时性的要求,请问这样使用分页 cache 真的合适吗?
cache 是为瞭解决性能问题,实时性要求很高就不能用 cache 了,或者要做 cache 及时更新机制
随机图文

Semantic Text Similarity - Identifying similar text based on meaning, not just keywords
语义文本相似度——基于意义而非关键词识别相似文本的应用 一、概述 1.1 什么是语义文本相似度 语义文本相似度是指通过计算文本之间的语义相似度来判断它们之间的相似程度,而不是简单地通过关键词匹配来判断。这种方法可以更准确地判断文本之间的相似度,提高文本处理的效率和准确性。 1.2 语义文本相似度的应用场景 语义文本相似度的应用场景非常广泛,包括文本匹配、问答系统、智能客服、搜索引擎等。 1.
企业通用dedecms模板
模板介绍: 模板名称:企业通用dedecms模板 简单大气的设计风格,适合机械类等企业使用,也是一款适用性比较大的模板,属于企业 通用类的,虽然简约但不简单! 网站截图: 首页: 330.zip 下载地址:-
2021瀚洋直播v2.2.69直播+抖音短视频+直播带货+朋友圈动态+远程礼
2021瀚洋直播v2.2.69直播+抖音短视频+直播带货+朋友圈动态+远程礼物+全场飘屏+幸运礼物+远程遥控主播+无人直播+自动发言+直播间带游戏(无限制完美运营版)三端互通,pc+安卓 Web+安卓+H5+短视频+vip守护+进场坐骑+主播pk+互动连麦+直播间红包+直播间幸运礼物+商城+进场提醒+收费房间试看 瀚洋直播系统功能亮点: 1直播带货(主播端可开店带货) 2抖音短视频(高仿抖音视频 
2019最美表演:胡歌一人饰三角 易烊千玺:下部戏有压力
内容加密



猜你喜欢
站点信息
- 文章统计: 442 篇文章
- 微信公众号:扫描二维码,关注我们
